Want to get a top ranking in search engines? No problem! All you need to do is add a few magical "meta tags" to your web pages, and you'll skyrocket to the top of the listings.
If only it were so easy. Let's make it clear:
- Meta tags are not a magic solution.
- Meta tags are not a magic solution.
- Meta tags are not a magic solution.
Meta tags have never been a guaranteed way to gain a top ranking on crawler-based search engines. Today, the most valuable feature they offer the web site owner is the ability to control to some degree how their web pages are described by some search engines. They also offer the ability to prevent pages from being indexed at all. This page explores these and other meta tag-related features in more depth.
Meta Tag Overview
What are meta tags? They are information inserted into the "head" area of your web pages. Other than the title tag (explained below), information in the head area of your web pages is not seen by those viewing your pages in browsers. Instead, meta information in this area is used to communicate information that a human visitor may not be concerned with. Meta tags, for example, can tell a browser what "character set" to use or whether a web page has self-rated itself in terms of adult content.
Let's review two common types of meta tags, and then we'll discuss exactly how they are used in more depth:

In the example above, you can see the beginning of the page's "head" area as noted by the HEAD tag -- it ends at the portion shown as /HEAD.
Meta tags go in between the "opening" and "closing" HEAD tags. Shown in the example is a TITLE tag, then a META DESCRIPTION tag, then a META KEYWORDS tag. Let's talk about what these do.
The Title Tag
The HTML title tag isn't really a meta tag, but it's worth discussing in relation to them. Whatever text you place in the title tag (between the TITLE and /TITLE portions as shown in the example) will appear in the reverse bar of someone's browser when they view the web page. For instance, within the title tag of this page that you are reading is this text:
How To Use HTML Meta Tags
If you look at the reverse bar in your browser, then you should see that text being used, similar to this:
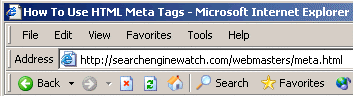
Some browsers also supplement whatever you put in the title tag by adding their own name, as Microsoft Internet Explorer is doing in the graphic above.
The title tag text is also used to describe your page when someone adds it to their "Favorites" or "Bookmarks" lists. For instance, if you added this page to your Favorites in Internet Explorer, it would show up like this:
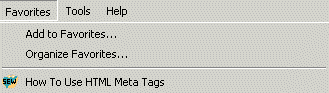
How did that little Search Engine Watch logo also show up? Everyone always asks. The article below provides more help:
Creating Your Own Favicon.ico Icon For IE5
Web Developer's Journal, March 7, 2000
http://www.webdevelopersjournal.com/articles/favicon.html
But what about search engines! The title tag is crucial for them. The text you use in the title tag is one of the most important factors in how a search engine may decide to rank your web page (see the Search Engine Placement Tips section for more details). In addition, all major crawlers will use the text of your title tag as the text they use for the title of your page in your listings.
For example, this is how Ask lists the page you are reading:
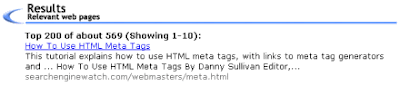
You can see that the text, "How To Use HTML Meta Tags," is used as the hyperlinked title of this page's listed in Ask's results.
In review, think about the key terms you'd like your page to be found for in crawler-based search engines, and then incorporate those terms into your title tag in short, descriptive fashion. That text will then be used as your title in crawler-based search engines, as well as the title in bookmarks, and in browser reverse bars.
The Meta Description Tag
The meta description tag allows you to influence the description of your page in the crawlers that support the tag (these are listed on the Search Engine Features page).
Look back at the example of a meta tag. See the first meta tag shown, the one that says "name=description"? That's the meta description tag. The text you want to be shown as your description goes between the quotation marks after the "content=" portion of the tag. Generally, 200 to 250 characters may be indexed, although only a smaller portion of this amount may be displayed.
For instance, I would like the page you are reading to be described in a search engine's listings like this:
This tutorial explains how to use HTML meta tags, with links
to meta tag generators and builders. From SearchEngineWatch.com,
a guide to search engine submission and registration.
Will this happen? Not necessarily with every search engine, and search engines may change how they treat meta tags at any given time. For example, Google typically ignores the meta description tag and instead will automatically generate its own description for this page based on content from the page that best matches the user query. If a meta desciption is the best match for the user query, Google may show that in its results. Other search engines may support the meta description tag partially. For instance, let's see again how this page is listed in Ask:

You can see that the first portion of the page's description comes from the meta description tag, then there's an ellipse (.), and the remaining portion is drawn from the body copy of the page itself.
In review, it is worthwhile to use the meta description tag for your pages because it gives you some degree of control with various crawlers. Often, an easy way to do this is to take the first sentence or two of body copy from your web page and use that for the meta description content.
The Meta Keywords Tag
The meta keywords tag allows you to provide additional text for crawler-based search engines to index along with your body copy. How does this help you? Well, for most major crawlers, it doesn't. That's because most crawlers now ignore the tag. The few supporting it can be found on the Search Engine Features page.
The meta keywords tag is sometimes useful as a way to reinforce the terms you think a page is important for the few crawlers that may support it, now or in the future. For instance, if you had a page about stamp collecting -- and you say the words stamp collecting at various places in your body copy -- then mentioning the words "stamp collecting" a few times in the meta keywords tag might help boost your page a bit higher for those words.
Remember, if you don't use the words "stamp collecting" on the page at all, then just adding them to the meta keywords tag is extremely unlikely to help the page rank well for the term. The text in the meta keywords tag, for the few crawlers that support it, works in conjunction with the text in your body copy.
The meta keyword tag is also sometimes useful as a way to help your page come up for synonyms or unusual words that don't appear on the page itself. For instance, let's say you had a page all about the "Penny Black" stamp. You never actually say the word "collecting" on this page. By having the word in your meta keywords tag, you may help increase the odds of coming up if someone searched for "penny black stamp collecting." Of course,you would greatly increase the odds, if you just used the word "collecting" in the body copy of the page itself.
Here's another example. Let's say you have a page about horseback riding, and you've written your page using "horseback" as a single word. You realize that some people may instead search for "horse back riding," with "horse back" in their queries being two separate words. If you listed these words separately in your meta keywords tag, then, maybe for the few crawlers that support it, your page might rank better for "horse back" riding. Sadly, the best way to ensure this happening would be to write your pages using both "horseback riding" and "horse back riding" in the text -- or perhaps on some of your pages, using the single-word version on some pages and the twoword version on others.
I'm emphasizing various phrases in this article on purpose. Far too many people new to search engine optimization obsess with the meta keywords tag. Few crawlers support it. For those that do, it might! maybe! perhaps! possibly! but with no guarantee! help improve the ranking of your page. It also may very well do nothing for your page at all. In fact, repeat a particular word too often in a meta keywords tag and you could actually harm your page's chances of ranking well. Because of this, I strongly suggest that those new to search engine optimization not worry about the tag at all.
Even those who are experienced in search engine optimization may decide it is no longer worth using this tag. Search Engine Watch doesn't. Any meta keywords tags you find in the site were written in the past, when the keywords tag was more important. There's no harm in leaving up existing tags you may have written, but going forward, writing new tags probably isn't worth the trouble. The articles below explores this in more detail:
Death Of A Meta Tag
The Search Engine Report, Oct. 1, 2002
Meta Tags Revisited
The Search Engine Report, Dec. 5, 2002
Still want to use the meta keywords tag? OK. Look back at the opening example. See the second meta tag shown, the one that says "name=keywords"? That's the meta keywords tag. The keywords you want associated with your page go between the quotation marks after the "content=" portion of the tag.
FYI, in the past, when the tag was supported by other search engines, they generally indexed up to 1,000 characters of text and commas were not required.
Meta Robots Tag
One other meta tag worth mentioning is the robots tag. This lets you specify that a particular page should not be indexed by a search engine. To keep spiders out, simply add this text between your head tags on each page that you don't want indexed. The format is shown the graphic below:

You do not need to use variations of the meta robots tag to help your pages get indexed. They are unnecessary. By default, a crawler will try to index all your web pages and will try to follow links from one page to another.
Most major search engines support the meta robots tag. However, the robots.txt convention of blocking indexing is more efficient, as you don't need to add tags to each and every page. See the Search Engines Features page for more about the robots.txt file. If you do use a robots.txt file to block indexing, there is no need to also use meta robots tags.
The meta robots tag also has some extensions offered by particular search engines to prevent indexing of multimedia content. The article below talks about this in more depth and provides some links to help files. Search Engine Watch members should follow the link from the article to the members-only edition for extended help on the subject.
Image Search Faces Renewed Legal Challenge
The Search Engine Report, August 22, 2001
Other Meta Tags
There are many other meta tags that exist beyond those explored in this article. For example, if you were to view the source code of this web page, you would find "author," "channel" and "date" meta tags. These mean nothing to web-wide crawlers such as Google. They are specifically for an internal search engine used by Search Engine Watch to index its own content.
There are also "Dublin Core" meta tags. The intent is that these can be used for both "internal" search engines and web-wide ones. However, no major web-wide search engine supports these tags. More about them can be found below:
How about the meta revisit tag? This tag is not recognized by the major search engines as a method of telling them how often to automatically return. They have never supported it.
In Conclusion
Overall, just remember this. Of all the meta tags you may see out there:
Meta Robots: This tag enjoys full support, but you only need it if you do not want your pages indexed.
Meta Description: This tag enjoys much support, and it is well worth using.
Meta Keywords: This tag is only supported by some major crawlers and probably isn't worth the time to implement.
Meta Everything Else: Any other meta tag you see is ignored by the major crawlers, though they may be used by specialized search engines.
More Resources
At the bottom of this page are more resources about meta tags, including tutorials and meta tag building applications. But first.
If you've been following the "Next" buttons to read the numbered sections of the Search Engine Submission Tips guide in order, you've now reached the last page. Congratulations!
There's still more information you might find helpful, however. Please review the pages listed under the Optional But Helpful section for additional assistance with search engine marketing issues.
In addition, do consider becoming a Search Engine Watch member, for access to even more information on search engine marketing issues.
Just started learning from this page? Don't worry -- click here to go to the beginning of the guide.
Now, here are those additional meta tag resources and articles.
Meta Tag Generators, Builders and Evaluators
SiteUp's Meta-Tag Generator
This is a software-based package for Windows that creates meta tags. It is a freeware package -- no registration fee required.
Meta Tag Builder
This form allows you to create very complicated meta tags using much more than the keywords and description tags, if you wish. Note that it will place a commented credit line into the tag. This can easily be removed, if you wish.
Articles About Meta Tags
Death Of A Meta Tag
The Search Engine Report, Oct. 1, 2002
Now supported by only one major crawler-based search engine, the value of adding meta keywords tags to pages seems little worth the time. A look at how we gained and lost the meta keywords tag.
Meta Tags Revisited
The Search Engine Report, Dec. 5, 2002
Follow-up to the article above.
Web spec targets for small businesses
ZDNet, Jan. 15, 2003
Discusses a new idea for allowing small and medium sized businesses to describe themselves to search engines through meta data in XML files. Given the bad history search engines have with meta data, I think it's unlikely you'll see this be accepted.
Are search engines dead?
WDVL, June 26, 2000
A look at the RDF meta data structure and how search engines aren't using it. Why not? Experience has taught them that meta data often cannot be trusted.
The New Meta Tags Are Coming -- Or Are They?
The Search Engine Report, Dec. 4, 1997
The proposed Resource Description Framework, or RDF, would provide a new way of describing web pages via meta data. There are high hopes for what it may accomplish, but support by the search engines isn't certain. Also learn more about the Dublin Core meta tags, which may be incorporated into the system.
What Is Meta Content Framework
Search Engine Watch, June 1997
Summary of a Netscape-backed meta data proposal now outdated by the rise of RDF (see above).
Source: http://searchenginewatch.com/showPage.html?page=2167931
Meta Tag Lawsuits
Page within Search Engine Watch that summarizes major lawsuits involving meta tags.
Note: the date shown on this article reflects updates provided by Claudia Bruemmer , Internet Marketing Writer and former ClickZ Managing Editor. This article was originally published by Danny






